Random Forests
Random Forest is a Supervised Machine Learning Algorithm that is used widely in Classification and Regression problems.
For this problem we used the Classification method.
Our problem predicts the quality of our wines. Our wines are classified as “Fair” or “Very Good” for the red and white wines.
Our wines have these features: alcohol, density, pH, residual sugar, free sulfur dioxide, chlorides, volatile acidity, total sulfur dioxide, citric acid, and fixed acidity.
We predicited our wines using 4 scenarios:
- Red wine – all features
- Red wine – top 8 features
- White wine – all features
- Red wine – top 8 features
Tunning the model:
We used different combinations of parameters and the GridSearchCV library. We choose the best accuracy rate avoiding overfitting and underfitting the model.

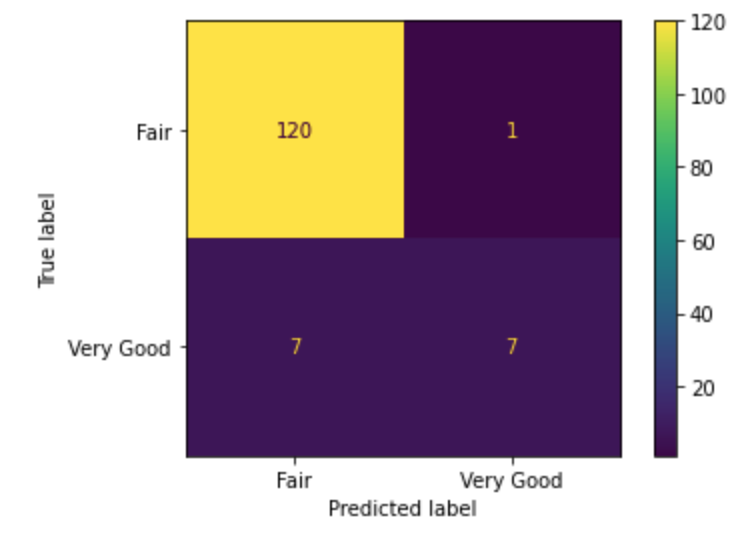
Red Wine (All Features):
Findings:
We got a final result of 93 %.
The classifier made 135 predictions (10% of data) and predict a total of 125 true positives and 10 false positives.
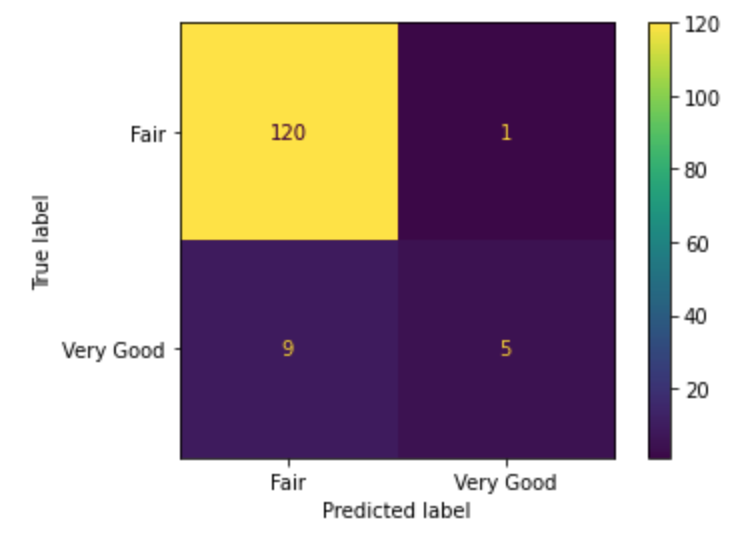
Red Wine (Top 8 Features):
Findings:
We got a final result of 94 %. A little higher result comparing with all features.
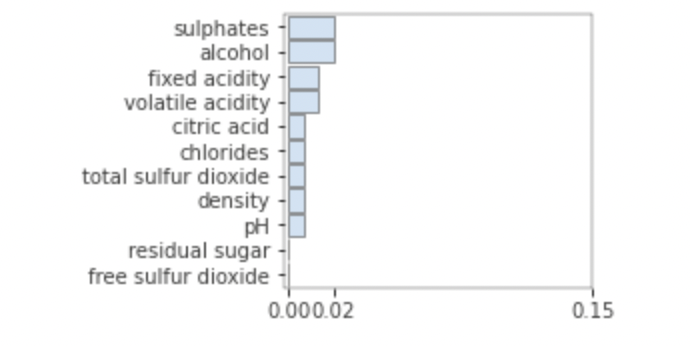
The Random Forests classifies the features after the first prediction.
We used the rfimp package for this classification
Features by Score Ranking:
The classifier made 135 predictions (10% of data) and predict a total of 127 true positives and 8 false positives.
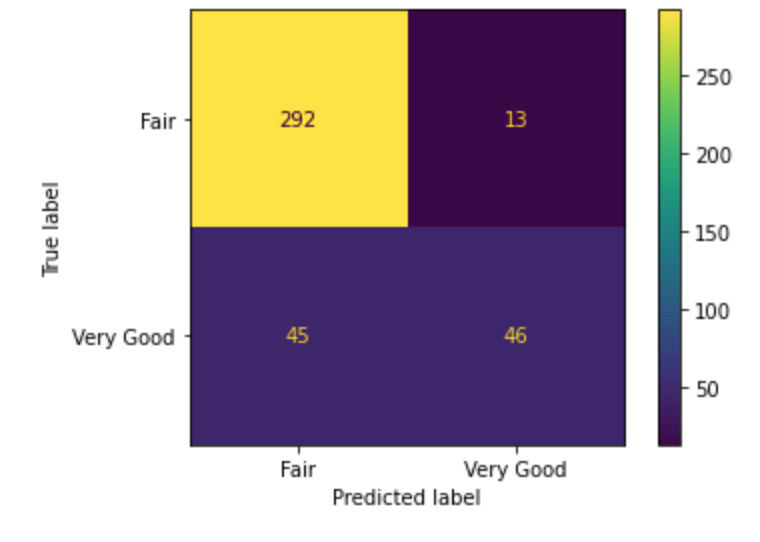
White Wine (All Features):
Findings:
We got a final result of 85 %.
The classifier made 396 predictions (10% of data) and predict a total of 338 true positives and 58 false positives.
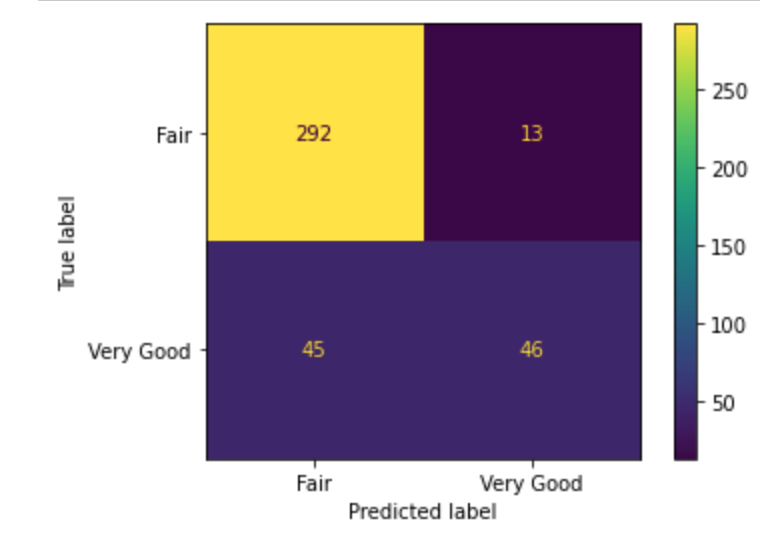
White Wine (Top 8 Features):
Findings:
We got a final result of 85 %. The same result as all features.
The Random Forests classifies the features after the first prediction.
We used the rfimp package for this classification
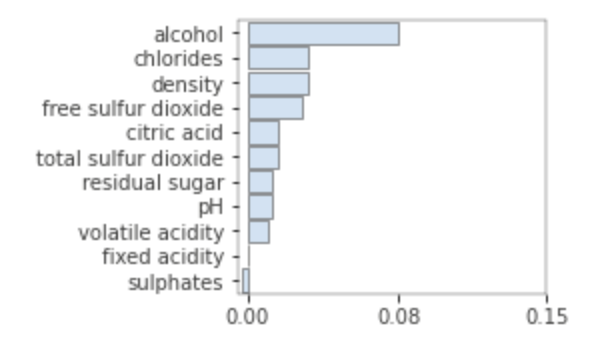
Features by Score Ranking:
The classifier made 396 predictions (10% of data) and predict a total of 338 true positives and 58 false positives.