XGBoost
XGBoost stands for eXtreme Gradient Boosting.
XGBoost is a decision-tree-based ensemble Machine Learning algorithm that uses a gradient boosting framework.
It provides a parallel boosting trees algorithm that can solve Machine Learning tasks.
We are going to use the XGBoost Classification method to predicts the quality of our wines. Our wines are classified as “Fair(0)” or “Very Good(1)” for the red and white wines.
Our wines have these features: alcohol, density, pH, residual sugar, free sulfur dioxide, chlorides, volatile acidity, total sulfur dioxide, citric acid, and fixed acidity.
We predicited our wines using 4 scenarios:
- Red wine – all features
- Red wine – top 8 features
- White wine – all features
- Red wine – top 8 features
Tunning the model:
We used different combinations of parameters and the GridSearchCV library. We choose the best accuracy rate avoiding overfitting and underfitting the model.

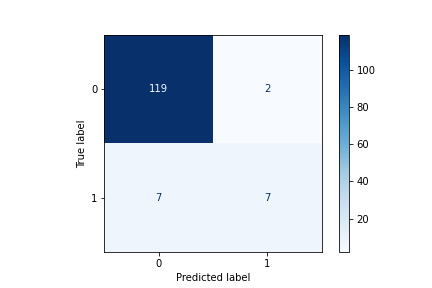
Red Wine (All Features):
Findings:
We got a final result of 93 %.
The classifier made 135 predictions (10% of data) and predict a total of 126 true positives and 9 false positives.
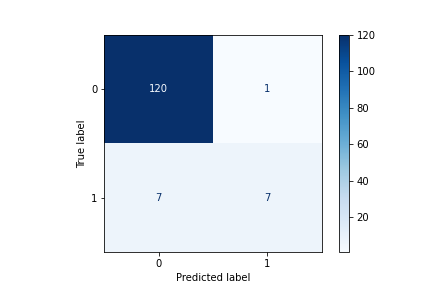
Red Wine (Top 8 Features):
Findings:
We got a final result of 94 %. A little higher result comparing with all features.
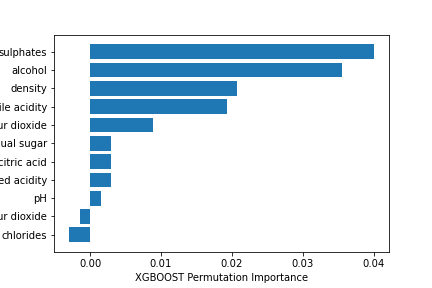
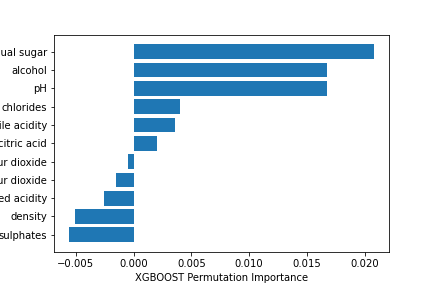
The XGBoost classifies the features after the first prediction.
We used Feature Importance computed with the Permutation method.
This permutation method will randomly shuffle each feature and compute the change in the model’s performance. The features which impact the performance the most are the most important ones.

The classifier made 135 predictions (10% of data) and predict a total of 127 true positives and 8 false positives.
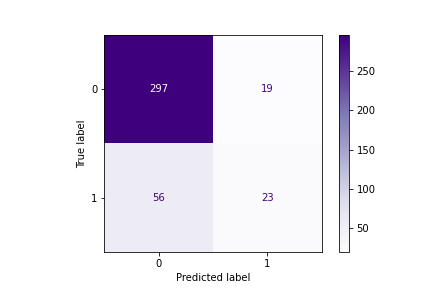
White Wine (All Features):
Findings:
We got a final result of 81 %.
The classifier made 395 predictions (10% of data) and predict a total of 320 true positives and 75 false positives.
White Wine (Top 8 Features):
Findings:
We got a final result of 82 %.
The XGBoost classifies the features after the first prediction.
We used Feature Importance computed with the Permutation method.
This permutation method will randomly shuffle each feature and compute the change in the model’s performance. The features which impact the performance the most are the most important ones.
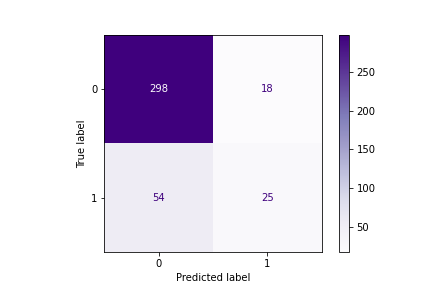
The classifier made 395 predictions (10% of data) and predict a total of 323 true positives and 72 false positives.
References: